
Real-Time Analytics: Why Speed Matters in the Age of AI
Introduction
In November 2024, JPMorgan Chase’s real-time fraud detection system blocked $23.7 million in fraudulent wire transfers within an average of 340 milliseconds of transaction initiation—preventing losses before money left the bank’s control and enabling legitimate transactions to complete without customer-facing delays. The system analyzes 175 billion events daily across 86 million customer accounts, applying machine learning models that evaluate transaction patterns, device fingerprints, geolocation data, and behavioral biometrics in real-time to calculate fraud probability scores. When scores exceed risk thresholds (calibrated to balance fraud prevention against false positive rates that would block legitimate transactions), the system automatically triggers interventions ranging from additional authentication requirements (step-up challenges) to immediate transaction blocks with fraud investigator alerts. During 2024, the real-time system achieved 94% fraud detection accuracy (true positive rate) while maintaining false positive rates below 0.8%—preventing fraud losses that would have exceeded $890 million annually while minimizing customer friction from unnecessary transaction denials. This performance represents 67% improvement over JPMorgan’s previous batch-processing fraud system that analyzed transactions hours after completion, when fraudulent transfers had already cleared and recovery became exponentially more difficult. The transformation exemplifies real-time analytics’ value proposition: in applications where timeliness directly affects outcomes—fraud prevention, algorithmic trading, predictive maintenance, dynamic pricing, autonomous systems—millisecond-scale analysis enables actions that batch processing rendered impossible, creating business value and competitive advantages that justify substantial technology investment.
From Batch to Stream: The Real-Time Analytics Revolution
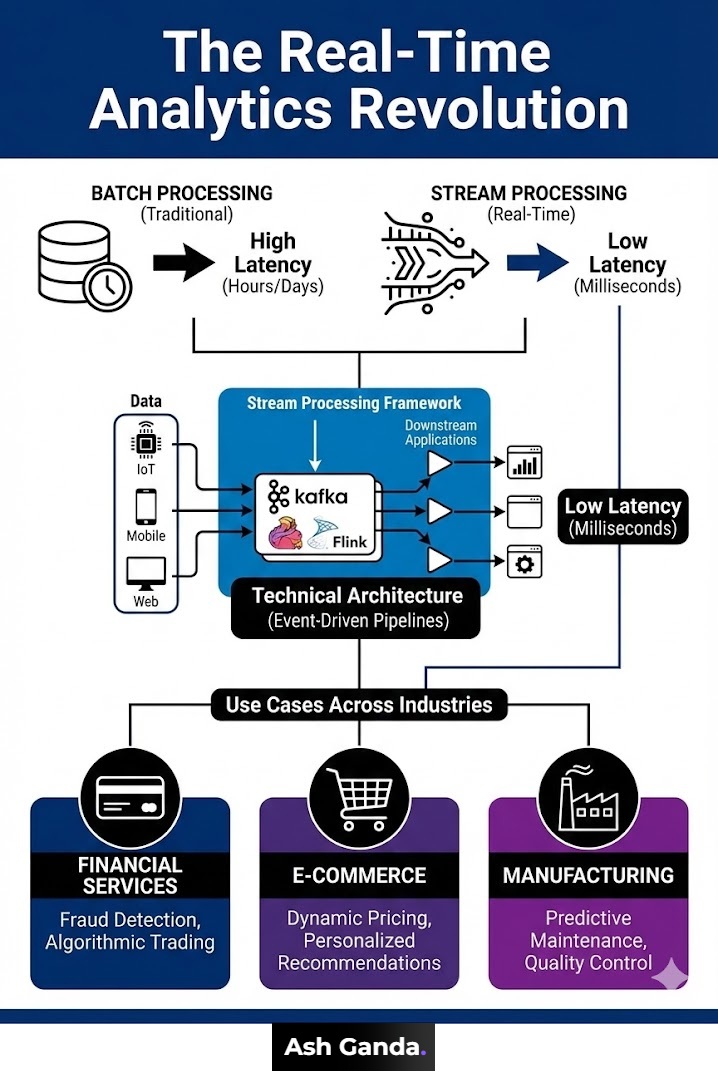
Traditional analytics follows a batch-processing paradigm: data accumulates in operational systems (databases, application logs, transaction systems) throughout the day, then nightly extract-transform-load (ETL) jobs move data to analytical data warehouses where analysts run queries and generate reports consumed the following morning. This architecture worked adequately when business decisions operated on daily or weekly cycles—inventory replenishment orders placed weekly based on sales reports, marketing campaigns adjusted monthly based on performance analysis, financial statements closed quarterly. However, digital transformation has compressed decision timelines: e-commerce prices change minute-by-minute responding to competitor actions and demand fluctuations, supply chains reroute shipments in response to disruptions detected from IoT sensors, and customer service systems personalize interactions based on real-time behavior analysis. Batch analytics’ 12-24 hour latency renders insights stale before they’re actionable—creating demand for real-time analytics processing data continuously as it’s generated.

Real-time analytics architectures process streaming data through event-driven pipelines rather than scheduled batch jobs. Apache Kafka, Apache Flink, and cloud-native services (AWS Kinesis, Google Cloud Dataflow, Azure Stream Analytics) provide distributed stream processing frameworks ingesting millions of events per second, applying transformations and analytics in-flight (within milliseconds), and routing results to downstream applications or dashboards. The architectural shift from batch to streaming involves three key differences: latency (milliseconds versus hours), processing model (continuous versus scheduled), and data freshness (current state versus historical snapshots). However, streaming architectures prove more complex than batch: managing state across distributed workers (tracking aggregations, joins across events), handling out-of-order events (data arriving non-chronologically due to network delays or system outages), and providing exactly-once processing semantics (ensuring each event affects results precisely once despite failures requiring replays) require sophisticated distributed systems engineering that batch processing’s simpler programming model avoids.
Use case characteristics determine whether real-time analytics justifies added complexity. Applications benefiting from real-time processing share three attributes: time-sensitive value (insights depreciate rapidly—fraud detection after money transfers is worthless, predictive maintenance after equipment failures provides no advantage), actionability (systems can automatically respond to insights—blocking transactions, adjusting prices, routing requests), and scale (high event volumes amortize infrastructure costs across millions of transactions). Conversely, applications lacking these characteristics—financial reporting (regulatory deadlines measured in weeks), marketing campaign analysis (adjustments occur weekly), HR analytics (workforce planning operates quarterly)—achieve adequate results with batch processing at lower cost and complexity. McKinsey research analyzing 340+ analytics deployments found that real-time systems delivered 3-5× higher ROI than batch processing for operational applications (fraud detection, personalization, predictive maintenance) but showed minimal advantage or even negative ROI for strategic applications (market research, financial planning, performance management)—highlighting the importance of matching architecture to use case requirements rather than adopting real-time processing universally.
Real-Time Analytics Use Cases Across Industries
Real-time analytics creates transformative value in domains where immediate insights enable actions impossible with batch processing, though implementation challenges vary by industry and application.
Financial services and fraud detection exemplify high-value real-time analytics where milliseconds determine outcomes. Beyond JPMorgan’s fraud prevention, algorithmic trading firms like Citadel Securities process market data feeds analyzing price movements, order flow, and news sentiment to execute trades within microseconds—speed advantages of milliseconds yield billions in profits through arbitrage opportunities that slower competitors miss. Visa’s real-time authorization system evaluates 500+ risk signals per transaction across its network processing 65,000 transaction messages per second globally, applying gradient-boosted decision trees (machine learning models balancing accuracy and inference speed) to calculate fraud scores within the 200-300 millisecond window between merchant authorization request and response—enabling seamless customer experience while blocking an estimated $25 billion in annual fraud. Real-time credit decisioning applies similar techniques: Affirm’s point-of-sale lending platform analyzes applicants’ credit bureau data, income verification, transaction history, and behavioral signals to approve or deny credit within 1-2 seconds at e-commerce checkout—conversion rates drop 67% when decisioning exceeds 5 seconds according to Affirm’s A/B testing, making sub-second latency critical for business viability. However, real-time financial systems face stringent regulatory requirements including audit trails, explainability (regulators demand transparency in decisioning), and fairness guarantees (avoiding discriminatory outcomes)—compliance obligations complicating technically sophisticated real-time implementations.
E-commerce and dynamic pricing leverage real-time analytics to optimize revenue through responsive pricing strategies. Amazon adjusts prices on 250+ million products millions of times daily based on competitor pricing (web scraping competitors every 15-30 minutes), inventory levels (discounting overstocked items, raising prices on scarce products), demand elasticity (testing price sensitivity through continuous experimentation), and individual customer propensity to purchase (personalized pricing within legal/ethical boundaries). Real-time pricing requires sophisticated analytics: predictive models forecast demand at different price points, optimization algorithms balance revenue maximization against strategic objectives (market share, customer lifetime value), and feedback loops measure price change effects enabling continuous improvement. Uber’s surge pricing exemplifies real-time supply-demand matching: when ride requests exceed available drivers in a geographic area, prices increase automatically—incentivizing more drivers to work while rationing limited supply to highest-value customers. The system recalculates prices every few minutes based on request rates, driver locations, and traffic conditions, with pricing algorithms trained through reinforcement learning on billions of historical rides. However, dynamic pricing creates customer perception challenges: consumers perceive frequent price changes as unfair even when economically rational, and algorithmic collusion concerns (multiple firms’ pricing algorithms implicitly coordinating to maintain high prices) have attracted regulatory scrutiny.
Telecommunications and network optimization deploy real-time analytics managing infrastructure serving billions of devices generating petabytes of data daily. Verizon’s network operations center analyzes 23 billion network events daily from cell towers, routers, and base stations, applying anomaly detection algorithms identifying degraded equipment, capacity bottlenecks, or security threats within seconds of occurrence. Real-time correlation analysis distinguishes localized issues (single cell tower failure affecting hundreds of customers) from systemic problems (core router degradation affecting millions)—enabling targeted remediation and appropriate escalation. Predictive models forecast network congestion 15-30 minutes in advance based on traffic patterns, event schedules, and weather (storms increase cellular usage as people shelter indoors), triggering proactive load balancing and capacity allocation preventing service degradation. AT&T’s Software-Defined Network (SDN) implementation uses real-time analytics to dynamically route traffic across its backbone network, achieving 99.999% uptime (5.26 minutes downtime annually) while reducing infrastructure costs 40% through utilization optimization—demonstrating how real-time intelligence improves both reliability and efficiency. Content delivery networks (CDNs) like Cloudflare and Akamai similarly optimize in real-time: routing user requests to optimal servers based on latency measurements, proactively caching content predicted to trend (news events, viral social media), and automatically mitigating DDoS attacks through traffic pattern analysis identifying malicious requests.
Manufacturing and predictive maintenance leverage real-time analytics preventing costly equipment failures and optimizing production. General Electric’s Predix platform monitors 340,000+ industrial assets (turbines, locomotives, medical imaging equipment) processing 50 million data points per day from IoT sensors measuring vibration, temperature, pressure, and electrical signatures. Machine learning models trained on historical failure data identify degradation patterns preceding breakdowns—detecting bearing wear 72 hours before failure with 89% accuracy, enabling scheduled maintenance during planned downtime rather than emergency repairs during production. GE Aviation’s engine monitoring prevents mid-flight incidents: aircraft transmit real-time telemetry from 250+ engine sensors via satellite, with ground-based analytics detecting anomalies (oil pressure fluctuations, temperature spikes, vibration signatures indicating component stress) triggering maintenance inspections after landing—system has prevented an estimated 340 in-flight shutdowns annually across GE’s commercial fleet. Real-time quality control applies computer vision analyzing products during manufacturing: Tesla’s Gigafactory cameras capture 1,200 images per vehicle during assembly, with neural networks detecting defects (paint imperfections, panel gaps, weld quality) in real-time, enabling immediate correction versus end-of-line inspection where rework proves 10× more expensive. However, industrial real-time analytics faces data integration challenges: legacy equipment uses proprietary protocols, operational technology (OT) networks remain isolated from IT networks for security, and equipment vendors resist sharing data—organizational and technical barriers requiring careful change management.
Media and content personalization exemplify consumer-facing real-time analytics optimizing engagement. Netflix’s recommendation system analyzes 450+ million viewing sessions daily, updating personalization models continuously as users watch, pause, rewind, or abandon content—improving recommendations’ relevance compared to batch-updated systems recalculating overnight. Real-time A/B testing evaluates UI changes, recommendation algorithms, and content positioning, with statistical analysis detecting performance differences within hours (versus weeks for traditional experiments) enabling rapid iteration. Spotify’s Discover Weekly playlist generation combines collaborative filtering (finding users with similar listening patterns) with natural language processing (analyzing song lyrics, reviews, blog posts) and audio analysis (extracting musical features from waveforms)—computations running continuously ingesting 60,000+ new tracks uploaded daily. Real-time analytics also combat fraud: YouTube’s Content ID system analyzes 500+ hours of video uploaded per minute, comparing audio fingerprints and visual hashes against copyrighted material database, flagging violations within minutes of upload for review—protecting intellectual property while maintaining creator ecosystem. Social media platforms like Twitter (X) apply real-time sentiment analysis and trend detection identifying viral content, breaking news, and emerging topics within seconds—surfacing relevant content before traditional media reports, though speed creates misinformation risks when false claims spread faster than fact-checking.
Technical Architecture and Technology Stack
Implementing production real-time analytics requires distributed systems infrastructure orchestrating data ingestion, stream processing, storage, and serving—with technology choices involving tradeoffs among latency, throughput, consistency, and operational complexity.
Data ingestion and message queues form the entry point for streaming data, buffering events from producers (applications, IoT devices, web servers) and delivering to consumers (processing applications, analytics systems) with guaranteed delivery and ordering semantics. Apache Kafka dominates enterprise streaming infrastructure: LinkedIn’s original motivation (consolidating 15+ fragmented data pipelines into unified streaming platform) has generalized to thousands of organizations processing trillions of messages daily through Kafka clusters. Kafka provides durable message storage (events persisted to disk enabling replay), horizontal scalability (partitioning topics across brokers handling millions of events per second), and pub-sub semantics (multiple consumers independently processing event streams)—capabilities enabling real-time analytics’ event-driven architecture. Cloud-native alternatives including AWS Kinesis, Google Cloud Pub/Sub, and Azure Event Hubs offer similar functionality with managed infrastructure reducing operational burden but less flexibility than self-hosted Kafka. Pulsar and NATS represent newer entrants emphasizing multi-tenancy (isolating different applications’ data streams) and geo-replication (synchronizing events across data centers for global deployments)—though ecosystem maturity lags Kafka’s extensive tooling and community.
Stream processing frameworks implement the computational logic analyzing event streams, applying transformations, joins, aggregations, and machine learning inference in real-time. Apache Flink provides stateful stream processing with exactly-once semantics—guaranteeing that each event affects results precisely once despite failures requiring computation restarts. Flink’s DataStream API enables complex event processing including windowing (aggregating events within time intervals), pattern detection (identifying event sequences matching templates), and iterative algorithms (graph computations requiring multiple passes over data). Flink’s checkpointing mechanism periodically persists computational state to durable storage, enabling recovery from failures without data loss or duplicate processing—critical for financial applications where exactly-once semantics prevent double-charging or missed fraud detection. Apache Spark Structured Streaming offers similar capabilities within Spark’s unified batch/stream API, enabling code reuse between historical analysis (batch) and real-time processing (streaming)—though latency typically higher than Flink (seconds versus milliseconds) due to micro-batch processing model. ksqlDB provides SQL interface to Kafka streams, enabling real-time analytics through familiar SQL syntax rather than programming APIs—lowering barriers for analysts versus engineers, though sacrificing flexibility for complex logic.
Stateful computation and state management create complexity distinguishing stream from batch processing. Real-time aggregations (calculating hourly revenue, tracking active user sessions, maintaining inventory counts) require maintaining state across events—but state must survive failures and scale beyond single machine memory. Frameworks provide distributed state stores: Flink’s RocksDB-backed state enables billions of keys tracked across worker nodes, with incremental checkpoints persisting state changes efficiently. However, large state introduces challenges: checkpointing multi-gigabyte state requires minutes completing (during which processing cannot progress), and state recovery after failures delays restart proportionally to state size. State optimization techniques including incremental aggregation (updating running totals rather than recalculating from scratch), state TTL (expiring old state to limit growth), and queryable state (exposing state stores for external queries enabling real-time dashboards) address challenges but require careful design—stateful streaming’s learning curve significantly steeper than stateless transformations.
ML model serving and feature stores enable real-time AI inference within streaming pipelines. Fraud detection requires millisecond-latency prediction from gradient-boosted trees or neural networks fed real-time features (transaction amount, merchant category, time since last transaction, device fingerprint)—necessitating optimized model serving infrastructure. Seldon, TensorFlow Serving, and Triton provide containerized model deployment with horizontal scaling, A/B testing, and monitoring—though integrating with streaming frameworks requires careful orchestration. Feature stores (Tecton, Feast, Hopsworks) solve the dual-timeline problem: ML models trained on historical data (batch features from data warehouses) but served in real-time (requiring same features computed from streaming data)—feature stores unify batch and streaming feature computation, ensuring training-serving consistency. However, real-time features are expensive: computing recency features (counts, averages over trailing time windows) for millions of entities (users, products, sessions) requires maintaining per-entity state—memory and computation costs scaling with entity count necessitate trade-offs between feature richness and system economics.
Data storage and serving provide durable persistence and low-latency access for real-time applications. Time-series databases (InfluxDB, TimescaleDB, Amazon Timestream) optimize for append-heavy workloads (sensor data, metrics, events) with efficient compression and time-range queries—enabling real-time dashboards visualizing millions of data points. NoSQL databases (Cassandra, DynamoDB, MongoDB) provide microsecond-latency reads/writes with horizontal scalability, suitable for user profiles, session state, and feature storage—though eventual consistency models create complexity ensuring data freshness. Redis and Memcached provide in-memory caching accelerating frequent queries—typical real-time architectures combine multiple storage technologies, routing different data types to appropriate systems. Analytics serving layers (Druid, Pinot, ClickHouse) provide OLAP (online analytical processing) on streaming data, enabling sub-second queries aggregating billions of events—Druid powers real-time dashboards at companies including Airbnb, Netflix, and Confluent, achieving query latencies less than 100ms on trillion-row datasets through column-oriented storage and inverted indexes.
Challenges and Tradeoffs in Real-Time Systems
Real-time analytics’ benefits come with substantial engineering challenges, operational complexity, and cost implications requiring careful evaluation against business requirements.
The CAP theorem and consistency tradeoffs create fundamental constraints: distributed systems cannot simultaneously guarantee consistency (all nodes see same data), availability (requests always receive responses), and partition tolerance (system operates despite network failures)—real-time systems must choose two of three. Financial transactions typically prioritize consistency (preventing double-spending, ensuring balances remain accurate) accepting availability impact during network partitions, while content recommendations prioritize availability (serving potentially stale recommendations better than errors) accepting eventual consistency. Implementing consistency requires distributed transactions and coordination protocols (two-phase commit, Paxos, Raft) introducing latency—millisecond-scale operations become multi-millisecond when consensus required. Organizations adopt eventual consistency where appropriate: LinkedIn’s social features tolerate seconds-delay propagating likes and comments, enabling high availability and low latency, while payment processing enforces strong consistency preventing monetary errors. However, eventual consistency complicates application logic: developers must reason about concurrent updates, conflict resolution, and compensating transactions—increased complexity versus simpler batch systems with single authoritative state.
Cost and resource utilization typically exceed batch processing: stream processing requires continuously running infrastructure (versus batch jobs utilizing compute only during execution), maintaining hot replicas for failover (ensuring availability during failures), and over-provisioning capacity handling traffic spikes (real-time systems cannot queue work for later processing without violating latency requirements). Uber’s real-time analytics infrastructure processes 100+ petabytes daily through 10,000+ server cluster—infrastructure costs exceeding $50 million annually according to industry estimates. Cloud pricing compounds costs: streaming data transfer between services incurs egress charges ($0.08-0.12 per GB), managed streaming services bill per shard-hour ($0.015-0.036 per shard-hour for Kinesis), and low-latency databases charge for throughput capacity (DynamoDB’s on-demand pricing: $1.25 per million writes)—costs scaling linearly with data volume and velocity. Organizations optimize through compression (reducing transfer costs), batching (amortizing per-request overhead), and autoscaling (matching capacity to load)—but real-time systems rarely achieve batch processing’s resource efficiency. The business question becomes whether reduced latency’s value (fraud prevention, improved user experience, operational efficiency) justifies 3-10× higher infrastructure costs—answer varies by application.
Operational complexity and skillset requirements create barriers to adoption. Operating distributed streaming infrastructure requires expertise spanning distributed systems, networking, storage, and performance optimization—skills scarcer and more expensive than traditional database administration or batch ETL development. On-call responsibilities increase: real-time systems require 24/7 monitoring and rapid incident response (latency spikes, processing lag, data quality issues) versus batch systems tolerating overnight failures fixed during business hours. Debugging stream processing proves challenging: reproducing bugs requires replaying event sequences, analyzing state evolution, and reasoning about timing-dependent behaviors—complexity exceeding stateless batch transformations. Organizations address operational challenges through managed services (cloud providers handling infrastructure operations), observability tooling (metrics, tracing, logging enabling rapid diagnosis), and gradual adoption (starting with high-value use cases, building expertise before expanding)—but fundamentally, real-time systems require more sophisticated technical capabilities than batch alternatives.
Data quality and schema evolution create additional challenges. Batch processing enables quality validation before downstream consumption—rejecting malformed data, applying cleansing rules, enforcing schema constraints—while stream processing must decide whether to drop invalid events (risking data loss), buffer for manual review (accumulating backlog), or forward with quality warnings (propagating issues downstream). Schema evolution—adding fields, changing types, restructuring data—proves particularly challenging: stream processors often maintain days-weeks of buffered data and checkpointed state, requiring backward compatibility ensuring old events remain processable. Organizations implement schema registries (Confluent Schema Registry, AWS Glue Schema Registry) enforcing compatibility rules, version schemas, and validate events before ingestion—governance overhead that batch systems with centralized ETL handle more simply. The lambda architecture pattern (running parallel batch and streaming pipelines, comparing results to detect discrepancies) provides safety net but doubles complexity—tradeoff between correctness guarantees and operational burden.
The Future of Real-Time Analytics: Trends and Evolution
Real-time analytics continues evolving through hardware advances (faster networks, specialized processors), software innovations (unified batch-stream frameworks, automated optimization), and emerging use cases (autonomous systems, real-time AI).
Unified batch and streaming frameworks aim to eliminate artificial distinction between historical analysis (batch) and real-time processing (streaming) through APIs handling both paradigms. Apache Beam provides portable abstraction executing on multiple runners (Flink, Spark, Cloud Dataflow)—developers write pipeline once, deploy across environments. Databricks’ Delta Lake combines data warehouse (ACID transactions, schema enforcement) with streaming (continuous ingestion, incremental processing), enabling unified analytics without separate batch/stream systems. However, unified frameworks face impedance mismatch: batch processing prioritizes throughput and cost-efficiency (acceptable to spend hours processing days of data), while streaming prioritizes latency (must process each event within milliseconds)—fundamentally different optimization objectives that unified systems struggle to satisfy simultaneously. The practical outcome is typically unified APIs simplifying development while implementations remain specialized—progress toward convergence but not complete unification.
Serverless stream processing abstracts infrastructure management, enabling developers to deploy streaming analytics without provisioning clusters, managing scaling, or handling failures. AWS Kinesis Data Analytics, Google Cloud Dataflow, and Azure Stream Analytics provide fully managed stream processing billed per event processed—economics shifting from fixed infrastructure costs to variable usage-based pricing. Serverless advantages include zero operational overhead (cloud provider handles scaling, failover, updates), pay-per-use economics (no costs during idle periods), and rapid deployment (minutes versus hours-days provisioning clusters). However, limitations include cold start latency (delays initializing serverless functions), vendor lock-in (proprietary APIs prevent portability), and cost unpredictability (high-volume processing can exceed self-hosted costs)—serverless suits intermittent or variable workloads but steady high-volume processing often more economical on dedicated infrastructure.
Real-time machine learning and AutoML are emerging, enabling continuous model training and deployment responding to data drift, concept drift, and emerging patterns. Continual learning systems update models incrementally as new data arrives rather than periodic retraining—Spotify’s recommendation models retrain hourly incorporating recent listening behavior, Amazon’s product recommendation models update continuously as customers browse and purchase. AutoML applied to streaming data automatically detects model degradation (accuracy declining due to distribution shift), explores alternative algorithms, tunes hyperparameters, and deploys improved models—reducing manual ML engineering. However, online learning introduces challenges including catastrophic forgetting (new data overwriting previous knowledge), stability-plasticity tradeoff (balancing adaptability against consistency), and validation complexity (ensuring updated models don’t degrade performance)—active research areas where techniques are maturing but not yet production-ready for all applications.
Edge analytics and fog computing push real-time processing closer to data sources, reducing latency and bandwidth by processing locally rather than centrally. Autonomous vehicles exemplify extreme edge analytics: sensor fusion, object detection, and path planning must complete within milliseconds on in-vehicle compute, as cloud round-trip latency (50-100ms) exceeds safety margins. Industrial IoT similarly benefits from fog computing: processing sensor data at factory gateways enables sub-millisecond control loops (robotic coordination, process adjustments) while transmitting only summaries to central analytics—reducing network costs and improving reliability (local processing continues during network outages). However, edge processing faces resource constraints (limited compute on embedded devices), fragmentation (heterogeneous hardware requiring different optimizations), and fleet management complexity (deploying updates to distributed devices)—challenges addressed by specialized edge platforms (AWS IoT Greengrass, Azure IoT Edge) but requiring careful architecture distinguishing edge versus cloud processing based on latency, bandwidth, and resilience requirements.

Conclusion and Strategic Recommendations
Real-time analytics has evolved from niche technology for high-frequency trading and telecom to mainstream capability enabling immediate insights and autonomous decision-making across industries. Key insights include:
- Demonstrated business value: JPMorgan prevented $890M annual fraud losses through 340ms real-time detection; Visa blocks $25B annually processing 65,000 transactions/second; GE prevents 340 in-flight engine failures through real-time telemetry
- Architectural shift: Streaming frameworks (Kafka, Flink) enable millisecond-latency processing replacing batch systems’ 12-24 hour delays—creating 1,000-100,000× latency reduction
- Use case selectivity: Real-time delivers 3-5× higher ROI for operational applications (fraud, personalization, predictive maintenance) versus strategic analytics where batch suffices—architecture should match requirements
- Engineering complexity: Stateful distributed processing, exactly-once semantics, and 24/7 operations require sophisticated capabilities—organizations need strong technical teams or managed services
- Cost-value tradeoffs: Real-time infrastructure costs 3-10× batch processing—justified when latency’s business value (fraud prevention, user experience, efficiency gains) exceeds infrastructure investment
Organizations should prioritize real-time analytics for use cases exhibiting time-sensitive value, actionability, and scale—starting with highest-ROI applications (fraud detection, dynamic pricing, predictive maintenance) before expanding to lower-value scenarios. Adopting managed services (cloud streaming platforms) reduces operational burden enabling focus on business logic rather than infrastructure. Building gradually—piloting with single use case, validating value, developing team capabilities, then expanding systematically—manages risk while capturing benefits. The future belongs to organizations that act on insights immediately rather than analyzing retrospectively—competitive advantage increasingly derives from decisioning speed, making real-time analytics strategic capability for digital-native enterprises.
Sources
- Kleppmann, M. (2017). Designing Data-Intensive Applications. Sebastopol, CA: O’Reilly Media. ISBN: 978-1449373320
- Narkhede, N., Shapira, G., & Palino, T. (2017). Kafka: The Definitive Guide. Sebastopol, CA: O’Reilly Media. ISBN: 978-1491936160
- Friedman, E., & Tzoumas, K. (2016). Introduction to Apache Flink: Stream Processing for Real Time and Beyond. Sebastopol, CA: O’Reilly Media. ISBN: 978-1491977170
- Akidau, T., et al. (2015). The Dataflow Model: A practical approach to balancing correctness, latency, and cost in massive-scale, unbounded, out-of-order data processing. Proceedings of the VLDB Endowment, 8(12), 1792-1803. https://doi.org/10.14778/2824032.2824076
- Carbone, P., et al. (2017). State management in Apache Flink: Consistent stateful distributed stream processing. Proceedings of the VLDB Endowment, 10(12), 1718-1729. https://doi.org/10.14778/3137765.3137777
- Marz, N., & Warren, J. (2015). Big Data: Principles and Best Practices of Scalable Realtime Data Systems. Shelter Island, NY: Manning Publications. ISBN: 978-1617290343
- Dunning, T., & Friedman, E. (2016). Streaming Architecture: New Designs Using Apache Kafka and MapR Streams. Sebastopol, CA: O’Reilly Media. ISBN: 978-1491953921
- Psaltis, A. G. (2017). Streaming Data: Understanding the Real-Time Pipeline. Shelter Island, NY: Manning Publications. ISBN: 978-1617292286
- McKinsey & Company. (2023). Real-time analytics: From insight to action. McKinsey Digital. https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/tech-forward/real-time-analytics
Mobile execution is where many digital strategies come to life. Awesome Apps publishes practical guides on app development and mobile UX.
Ash Ganda is the founder of Ganda Tech Services, a Sydney-based technology consultancy delivering cloud, web, and mobile solutions for Australian businesses.
About the Author
Ashish Ganda is the founder of Ganda Tech Services, a Sydney-based technology consultancy specialising in cloud infrastructure, web development, and mobile app solutions for Australian businesses.
Digital Transformation Roadmap 2026
A 12-month framework for Australian SMBs ready to modernise — phases, tools, and milestones.