
Enterprise Data Catalog and Governance Strategy: Building the Foundation for Data-Driven Decisions
Introduction
The modern enterprise drowns in data while thirsting for information. Petabytes accumulate across cloud warehouses, data lakes, operational databases, SaaS applications, and legacy systems. Yet when business users need data for decisions, they often cannot find it. When they find it, they cannot understand it. When they understand it, they cannot trust it.
This is the data discoverability crisis: organisations invest heavily in data infrastructure but realise diminishing returns because data remains locked in silos, poorly documented, and accessible only to those with tribal knowledge of where things live.
Data catalogs address this crisis by creating a searchable, governed inventory of enterprise data assets. Combined with effective data governance, catalogs transform data from a liability requiring management into an asset enabling decisions. The organisations mastering this capability gain competitive advantage through faster, more confident data-driven decisions.
This guide provides the strategic framework for implementing enterprise data catalogs with integrated governance—not as a technology project, but as an organisational capability.
The Data Catalog Value Proposition
What Data Catalogs Actually Do
At its core, a data catalog provides:
Discovery: Finding data assets through search, browse, and recommendations. Users locate datasets, tables, reports, and other data assets without knowing their physical location.
Understanding: Comprehending what data means through descriptions, schemas, lineage, and usage context. Users understand whether data fits their needs without extensive investigation.
Trust: Assessing data quality, freshness, and reliability. Users determine whether data can be trusted for their specific use case.
Access: Obtaining appropriate access to data through integrated request workflows. Users request and receive access without navigating complex approval chains.
Governance: Enforcing policies around data usage, retention, and compliance. Organisations maintain control while enabling access.
Business Value Realisation
Data catalogs deliver value across multiple dimensions:
Analyst Productivity

Data analysts spend 30-50% of their time finding and understanding data before analysis begins. Effective catalogs reduce this dramatically:
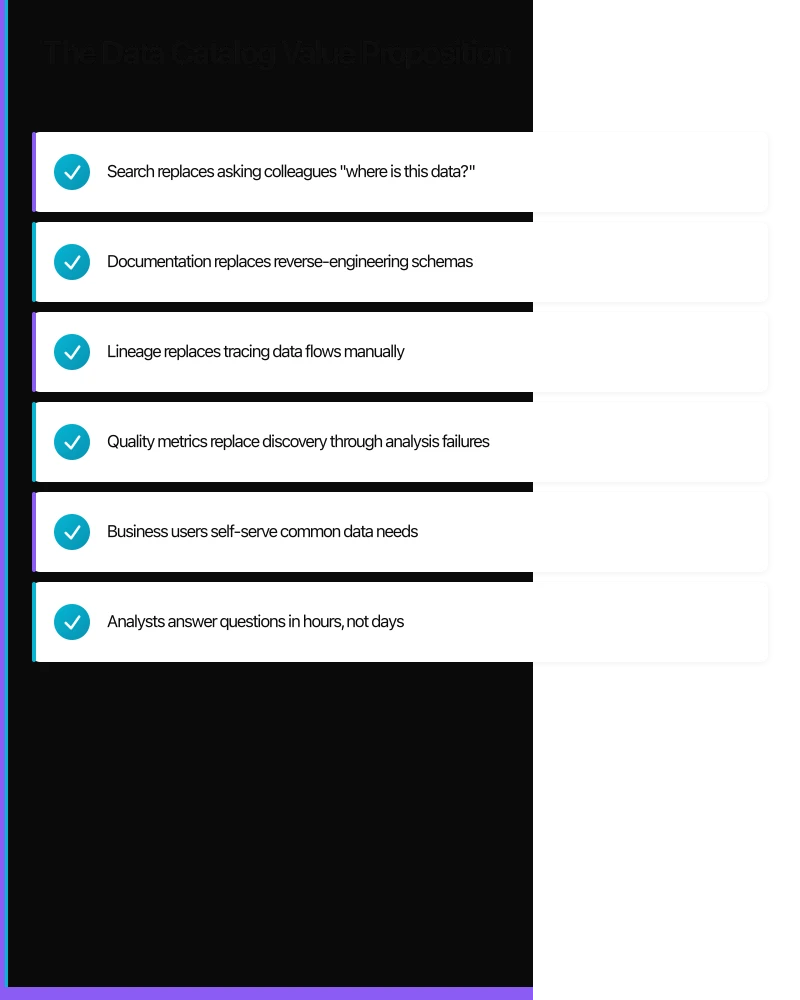
- Search replaces asking colleagues “where is this data?”
- Documentation replaces reverse-engineering schemas
- Lineage replaces tracing data flows manually
- Quality metrics replace discovery through analysis failures
Decision Velocity
Faster data access accelerates decisions:
- Business users self-serve common data needs
- Analysts answer questions in hours, not days
- New data sources integrate into decision workflows faster
- Cross-functional analysis becomes feasible
Risk Reduction
Governance integration reduces data-related risk:
- Sensitive data discovery prevents compliance violations
- Access controls prevent unauthorised use
- Lineage enables impact analysis for changes
- Quality monitoring catches issues before decisions based on bad data
AI and Analytics Enablement
Modern AI initiatives depend on data findability:
- Feature stores build on cataloged data assets
- Model training requires understood, quality data
- RAG systems need indexed, searchable content
- Analytics democratisation requires data literacy support
The Data Catalog Landscape
Platform Categories
The market offers multiple approaches to data cataloging:
Standalone Data Catalogs
Purpose-built platforms focused on cataloging capabilities:
- Alation: Market leader with strong collaboration features
- Collibra: Governance-focused with extensive policy capabilities
- Atlan: Modern, user-experience-focused platform
- data.world: Knowledge-graph-based discovery
Strengths: Deep cataloging features, cross-platform coverage Considerations: Additional platform to operate, integration requirements
Cloud-Native Catalog Services
Catalogs provided by cloud data platforms:
- AWS Glue Data Catalog: Native to AWS analytics ecosystem
- Azure Purview (Microsoft Purview): Microsoft’s unified governance
- Google Dataplex: Google Cloud’s data fabric approach
Strengths: Native integration, reduced operational burden Considerations: Limited to that cloud’s ecosystem, feature depth varies
Data Platform Integrated Catalogs
Catalogs embedded within data platforms:
- Databricks Unity Catalog: Integrated with Databricks lakehouse
- Snowflake Horizon: Snowflake’s governance and discovery layer
- dbt Cloud: Metadata from transformation lineage
Strengths: Deep platform integration, automatic metadata Considerations: Limited to that platform’s data
Open Source Options
Community-driven alternatives:
- Apache Atlas: Hadoop ecosystem standard
- DataHub (LinkedIn): Modern metadata platform
- OpenMetadata: Emerging open standard

Strengths: No licensing cost, community innovation Considerations: Operational burden, feature maturity
Selection Framework
Evaluate platforms against these dimensions:
Metadata Coverage
- What data sources can it connect to?
- What metadata types does it capture (technical, business, operational)?
- How automated is metadata ingestion?
- Can it handle your specific data platforms?
Discovery Experience
- How intuitive is search and browse?
- Does it provide recommendations and suggestions?
- Can business users navigate without technical knowledge?
- What collaboration features exist (comments, ratings, wikis)?
Governance Capabilities
- Can it discover and classify sensitive data?
- What access control models does it support?
- How does it integrate with identity management?
- What policy enforcement mechanisms exist?
Lineage and Impact Analysis
- How does it capture data lineage?
- Can it show end-to-end flows across systems?
- Does it enable impact analysis for changes?
- How granular is lineage (table, column, value)?
Quality Integration
- Does it integrate with data quality tools?
- Can it display quality metrics alongside metadata?
- Does it support quality rule definition?
- How does it alert on quality issues?
Scalability and Operations
- What’s the deployment model (SaaS, self-hosted, hybrid)?
- How does it handle enterprise-scale metadata?
- What’s the operational burden?
- What’s the total cost of ownership?
Implementation Strategy
Phase 1: Foundation and Planning (Months 1-2)
Stakeholder Alignment
Data catalog success requires cross-functional alignment:
Data Consumers: Business analysts, data scientists, business users who need to find and understand data. Understand their pain points and requirements.
Data Producers: Engineers, analysts, and teams who create and maintain data assets. They must contribute metadata for the catalog to have value.
Data Governance: Compliance, risk, and governance stakeholders who need policy enforcement. Catalog must integrate with governance requirements.
Technology: IT and platform teams who will operate and integrate the catalog. They need manageable operational burden.
Current State Assessment
Inventory existing metadata assets:
- What metadata exists today and where?
- What documentation exists for data assets?
- What governance processes exist?
- What tools already capture metadata?
Scope Definition
Define initial scope realistically:
- Which data domains will be cataloged first?
- Which user personas will be served initially?
- What governance requirements must be met?
- What success looks like in 6 months?
Phase 2: Platform Selection and Setup (Months 2-4)
Vendor Evaluation
Structured evaluation process:
- Develop requirements based on stakeholder input
- Issue RFI to candidate vendors
- Shortlist 3-4 for detailed evaluation
- Conduct POC with actual data sources
- Reference checks with similar organisations
Technical Implementation
Deploy catalog infrastructure:
- Environment provisioning (cloud, network, security)
- Identity integration (SSO, role mapping)
- Initial connector configuration
- Security baseline implementation
Integration Architecture
Design integration approach:
- Automated metadata ingestion from data platforms
- Manual enrichment workflows
- Lineage capture mechanisms
- Quality metric integration
Phase 3: Initial Population (Months 4-6)
Automated Metadata Ingestion
Connect priority data sources:
- Data warehouses (Snowflake, BigQuery, Redshift)
- Data lakes (S3, ADLS, GCS)
- Databases (operational systems)
- BI tools (Tableau, Looker, Power BI)
- Transformation tools (dbt, Airflow)
Business Metadata Enrichment
Technical metadata alone has limited value. Enrich with business context:
- Business descriptions explaining what data means
- Owner and steward assignments
- Domain and classification tagging
- Quality tier and trust indicators
- Usage guidance and caveats
Governance Policy Configuration
Implement governance controls:
- Sensitive data classification rules
- Access policy definitions
- Data retention policies
- Compliance requirement mapping
Phase 4: Adoption and Expansion (Months 6-12)
User Onboarding
Drive adoption across the organisation:
- Training sessions for different user personas
- Documentation and self-service guides
- Champions network in each business area
- Success story communication
Feedback and Iteration
Improve based on usage:
- Monitor search success rates
- Track metadata completeness
- Gather user feedback
- Iterate on organisation and classification
Scope Expansion
Extend to additional domains:
- Add data sources based on demand
- Expand governance coverage
- Deepen lineage and quality integration
- Build advanced features (recommendations, automation)
Governance Integration
Data Governance Operating Model
Catalogs enable governance; governance gives catalogs meaning. Design the operating model:
Governance Roles
Data Owners: Business leaders accountable for data domains. They approve access, set policies, and ensure data meets business needs.
Data Stewards: Practitioners responsible for data quality and metadata within domains. They maintain documentation, monitor quality, and address issues.
Data Custodians: Technical teams managing data systems. They implement technical controls and maintain infrastructure.
Governance Processes
Data Classification: Systematic categorisation of data by sensitivity, criticality, and regulatory status. Classification drives access controls and handling requirements.
Access Management: Processes for requesting, approving, and revoking data access. Balance security with usability.
Quality Management: Monitoring, measurement, and improvement of data quality. Define quality dimensions and thresholds by data tier.
Lifecycle Management: Policies for data retention, archival, and deletion. Ensure compliance while managing storage costs.
Policy Enforcement Patterns
Governance policies need enforcement mechanisms:
Preventive Controls
Stop policy violations before they occur:
- Access controls preventing unauthorised queries
- Masking sensitive data automatically
- Blocking non-compliant data movements
- Approval workflows for sensitive access
Detective Controls
Identify policy violations when they occur:
- Access monitoring and anomaly detection
- Quality monitoring against thresholds
- Compliance scanning for policy drift
- Usage pattern analysis
Corrective Controls
Remediate violations after detection:
- Automated remediation where possible
- Incident response workflows
- Root cause analysis processes
- Policy refinement based on incidents
Sensitive Data Discovery
Modern catalogs provide automated sensitive data discovery:
Classification Techniques
- Pattern matching (SSN, credit card, email formats)
- Machine learning classification (PII, PHI detection)
- Metadata analysis (column names suggesting sensitivity)
- Sampling and content analysis
Classification Governance
- Define classification taxonomy
- Set confidence thresholds for automated classification
- Establish review workflows for uncertain classifications
- Maintain classification over time as data evolves
Driving Adoption
The Adoption Challenge
Technical implementation is insufficient. Catalogs provide value only when used. Common adoption barriers:
Metadata Quality: Incomplete or inaccurate metadata frustrates users who then don’t return.
Discovery Experience: Poor search or navigation makes finding data harder than asking colleagues.
Governance Friction: Excessive access controls prevent legitimate use and drive shadow data practices.
Cultural Resistance: “We’ve always done it this way” resistance to new tools and processes.
Adoption Strategies
Start with Pain Points
Identify specific, painful use cases and solve them:
- New analyst onboarding (where’s the data I need?)
- Compliance reporting (where is our PII?)
- Impact analysis (what breaks if we change this?)
Champions Network
Build a network of advocates:
- Identify enthusiastic early adopters
- Give them advanced training and support
- Leverage their networks for organic adoption
- Celebrate their successes publicly
Integrated Workflows
Embed catalog into existing workflows:
- Links from BI tools to catalog entries
- Catalog search from data platform interfaces
- Access requests from within analytics tools
- Lineage from transformation tool outputs
Metrics and Incentives
Measure and incentivise adoption:
- Track catalog usage metrics (searches, views, contributions)
- Incorporate catalog use into analyst onboarding
- Recognise stewards maintaining high-quality metadata
- Include catalog metrics in data team OKRs
Measuring Success
Adoption Metrics
Usage Metrics
- Daily/weekly active users
- Searches performed
- Data assets viewed
- Access requests submitted
Contribution Metrics
- Metadata completeness scores
- New descriptions added
- Quality certifications completed
- Steward engagement rates
Outcome Metrics
Productivity Metrics
- Time to find data (surveys, studies)
- Self-service resolution rate
- Analyst onboarding time
- Data request turnaround
Quality Metrics
- Data quality score trends
- Issues discovered through catalog
- Remediation rates
- Quality-related incident reduction
Governance Metrics
- Sensitive data coverage
- Access review completion
- Policy compliance rates
- Audit finding reduction
Business Impact Metrics
Decision Velocity
- Time from question to answer
- Analysis cycle time
- Report refresh frequency
Risk Reduction
- Compliance audit performance
- Data breach indicators
- Regulatory finding trends
The AI-Enabled Future
Data catalogs are evolving rapidly with AI integration:
Intelligent Search
Natural language queries replacing keyword search. Users ask “What customer data do we have from the last quarter?” rather than constructing Boolean queries.
Automated Documentation
AI-generated descriptions and documentation from data analysis. Reduces the burden of manual metadata creation.
Recommendation Engines
Suggesting relevant datasets based on user role, query history, and peer behaviour. Surfaces data users didn’t know existed.
Quality Inference
Automated quality assessment and anomaly detection. Proactive alerts when data quality degrades.
Governance Automation
Intelligent policy suggestions based on data characteristics. Automated classification confidence improving over time.
Conclusion
Enterprise data catalogs have evolved from nice-to-have metadata repositories to essential infrastructure for data-driven organisations. The combination of increasing data volume, regulatory pressure, and AI opportunities makes data discoverability and governance critical capabilities.
Success requires treating catalog implementation as an organisational initiative, not a technology project:
- Align stakeholders around shared goals for data accessibility and governance
- Select platforms based on your specific ecosystem and requirements
- Invest in metadata quality as the foundation of catalog value
- Integrate governance to make the catalog authoritative
- Drive adoption through solving real pain points and integrating workflows
- Measure outcomes that connect to business value, not just tool usage
The organisations that master data cataloging and governance will move faster, with more confidence, than competitors still navigating data chaos. The investment pays dividends across every data initiative that follows.
Start with the business problems. Build the foundation. Iterate toward excellence.
Sources
- Gartner. (2025). Market Guide for Active Metadata Management. Gartner Research. https://www.gartner.com/en/documents/metadata-management
- DAMA International. (2015). DAMA-DMBOK: Data Management Body of Knowledge (2nd ed.). Technics Publications.
- Ladley, J. (2015). Data Governance: How to Design, Deploy, and Sustain an Effective Data Governance Program (2nd ed.). Academic Press.
- Seiner, R. S. (2014). Non-Invasive Data Governance. Technics Publications.
- Atlan. (2025). State of Data Cataloging. Atlan Research. https://atlan.com/data-catalog-report/
- Monte Carlo. (2025). Data Quality Survey. Monte Carlo Data. https://www.montecarlodata.com/data-quality-survey/
Strategic guidance for enterprise technology leaders building data-driven organisations.
For hands-on web development and SEO advice, visit Cosmos Web Tech — our specialist web design and digital marketing blog.
These insights are drawn from my work leading Ganda Tech Services — helping Australian businesses navigate digital transformation through cloud, web, and mobile.
About the Author
Ashish Ganda is the founder of Ganda Tech Services, a Sydney-based technology consultancy specialising in cloud infrastructure, web development, and mobile app solutions for Australian businesses.
Digital Transformation Roadmap 2026
A 12-month framework for Australian SMBs ready to modernise — phases, tools, and milestones.