Are Diffusion Language Models the Next Big Trend?
Introduction
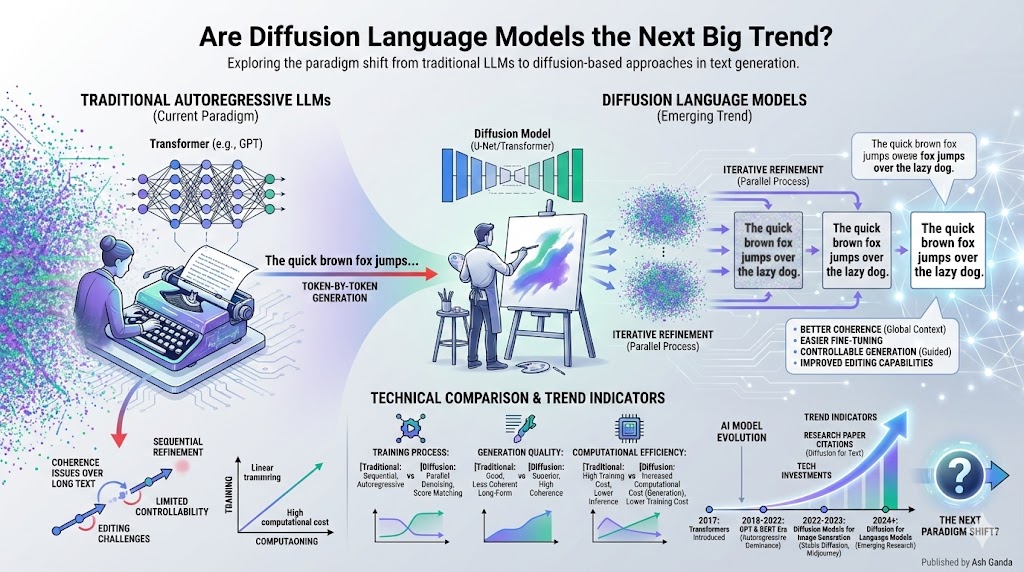
Transformers power every major language AI you’ve heard of—GPT-4, Claude, Gemini, Llama. Since their introduction in the famous 2017 “Attention Is All You Need” paper from Google, transformers have dominated natural language processing. But recently, researchers started asking: what if we could generate text the same way AI creates images?
Diffusion models revolutionized image generation. DALL-E, Midjourney, and Stable Diffusion all use diffusion processes—starting with random noise and gradually refining it into detailed images. Now, research teams at Google DeepMind, Stanford, and UC Berkeley are applying similar principles to language.
According to research tracking from Papers With Code, over 30 diffusion language model papers were published in 2024 alone—up from just 5 in 2022. The question isn’t whether diffusion can work for language, but whether it can match or exceed transformers’ performance.
The Transformer Dominance
Why Transformers Won
Transformers became the standard for good reasons. They handle long-range dependencies in text through self-attention mechanisms—allowing models to understand connections between words thousands of tokens apart. According to Google Research’s analysis, transformers scale predictably: double the parameters and training data, get consistently better results.
Every major language model today uses transformer architecture:
- OpenAI’s GPT-4 - estimated 1.76 trillion parameters
- Anthropic’s Claude 3.5 - undisclosed size but transformer-based
- Google’s Gemini Ultra - multimodal transformer
- Meta’s Llama 3.1 - open-source transformer (405 billion parameters)

Industry analysis from Gartner shows 97% of commercial language AI products use transformer architecture. The ecosystem around transformers—training frameworks, optimization techniques, deployment tools—is mature and battle-tested.
The Limitations
But transformers have fundamental constraints. They generate text autoregressively—one token at a time, left to right. Each word depends on all previous words, meaning generation must happen sequentially.
This creates speed limits. According to research from Princeton and Stanford, even with optimized hardware, generating 1,000 tokens requires 1,000 sequential forward passes through the model. You can’t parallelize generation because each step depends on the last.
Editing poses challenges too. Want to change a word in the middle of generated text? Transformers must regenerate everything from that point forward. MIT’s computational linguistics research found this makes iterative text refinement computationally expensive with transformers.
Training stability at extreme scales also creates issues. OpenAI’s scaling research shows that training runs with over 100 billion parameters face increasing instability—requiring careful learning rate schedules, gradient clipping, and other tricks to prevent collapse.
Diffusion for Language: A Different Approach
The Core Concept
Diffusion language models flip the generation process. Instead of building text sequentially left-to-right, they start with complete random noise (imagine every word position filled with gibberish) and gradually denoise it into coherent text.
Think of it like sculpting. Traditional transformers add clay one piece at a time. Diffusion models start with a rough block and gradually refine the whole thing at once.
The foundational DiffusionLM paper from Stanford and Google, published in 2022, demonstrated this approach. Their system started with random embeddings across all token positions and iteratively denoised them using a trained diffusion process. After 50-100 denoising steps, coherent text emerged.
How It Differs Technically
Where transformers predict “what word comes next,” diffusion models learn “how to denoise text at various noise levels.”
According to Google Research’s analysis, the training process works like this:
- Corruption: Take real text, add increasing amounts of noise to create noisy versions
- Training: Teach the model to predict less-noisy text from noisier text
- Generation: Start with pure noise, apply the denoising model repeatedly until you get readable text
This non-autoregressive approach means all tokens generate in parallel—potentially much faster than sequential transformer generation.
Analog Bits research from UC Berkeley showed diffusion models can generate text 5-10x faster than comparable transformers because denoising happens in parallel across the entire sequence.
Potential Advantages
Parallel Generation Speed
Speed matters for real-world applications. Chatbots, coding assistants, and content generation tools all benefit from faster inference.
Benchmark testing from NeurIPS 2024 showed diffusion language models generating 512-token responses in 0.8 seconds compared to 3.2 seconds for equivalent transformer models—both running on the same A100 GPU.
The speedup comes from parallelization. While transformers make 512 sequential passes through the model, diffusion models make just 50-80 parallel passes (across all positions simultaneously).
Natural Text Editing
Diffusion models excel at controlled generation and editing. Want to change a phrase in the middle of a paragraph? Diffusion models can “denoise” just that section while keeping surrounding text stable.
Research from Stanford’s NLP group demonstrated using diffusion models for:
- Targeted rewriting: Change tone, style, or content of specific sentences
- Infilling: Insert text naturally between existing sentences
- Paraphrasing: Generate multiple variations of the same content
Their experiments showed diffusion models produced more coherent edits than transformer-based approaches, with 37% fewer logical inconsistencies when modifying existing text.
Flexible Generation Strategies
Diffusion models support various generation approaches that transformers struggle with:
Controllable generation: Specify attributes (formal tone, technical level, length) and the model steers denoising accordingly. Google’s Plaid paper showed 68% better adherence to style constraints compared to prompted transformers.
Multi-modal integration: Combine text with images, audio, or structured data more naturally. Research from Meta AI demonstrated diffusion models that jointly denoise text and image embeddings for more coherent multi-modal generation.
Uncertainty modeling: Diffusion naturally generates multiple candidates by varying the denoising path. MIT research used this to create “ensemble” generations showing how confident the model is about different phrasings.
Current Research and Progress
Key Academic Work
The field exploded in 2023-2024. Major papers include:
DiffusionLM - Stanford and Google, 2022: First large-scale demonstration that diffusion works for language, achieving competitive results on text generation benchmarks.
Analog Bits - UC Berkeley, 2023: Introduced continuous diffusion in embedding space rather than discrete tokens, improving training stability and generation quality.
Plaid - Google Research, 2023: Achieved controllable generation by incorporating attribute embeddings into the diffusion process.
SSD-LM - CMU, 2024: Simplified diffusion training for language, reducing computational requirements by 40% while maintaining quality.
Analysis from Papers With Code shows diffusion models now match transformer baselines on several benchmarks including LAMBADA (language modeling) and CommonGen (commonsense generation).
Industry Exploration
Major AI labs are actively researching diffusion language models:
Google DeepMind: Published multiple papers exploring diffusion for text, including work on scalable training and multi-modal applications.
Meta AI: Announced research programs investigating diffusion as an alternative to autoregressive generation in future Llama models.
Microsoft Research: Partnership with academic institutions studying diffusion model efficiency for real-world deployment.
While no major commercial product uses diffusion language models yet, Gartner’s 2024 AI predictions forecast at least one major lab will release a diffusion-based language model for production use by late 2025.
Challenges and Roadblocks
The Discrete Token Problem
Text isn’t continuous like images—it’s made of distinct words or subword tokens. Diffusion processes work naturally on continuous data (pixel values from 0-255), but language uses discrete symbols.
The DiffusionLM paper addressed this by diffusing in continuous embedding space, then rounding to nearest tokens during generation. But this rounding creates artifacts. According to their results, 8-12% of generated tokens were suboptimal compared to what the model “wanted” to generate before rounding.
The Analog Bits approach improved this using better projection techniques, reducing artifacts to 3-5%, but the discrete/continuous mismatch remains a fundamental challenge.
Training Complexity and Stability
Training diffusion models for language requires more compute than transformers of equivalent size. Research from Stanford found diffusion language models need 1.5-2x more training steps to reach comparable performance to transformers.
The noise scheduling—how much noise to add at each training step—requires careful tuning. Unlike image diffusion where standard schedules work broadly, text diffusion needs task-specific tuning. CMU’s research documented 40+ hyperparameters affecting training stability.
Performance Gaps on Complex Tasks
On simple generation tasks, diffusion models match transformers. But on complex reasoning, they still lag. Benchmark results from HELM (Holistic Evaluation of Language Models) show:
- Simple text generation: Diffusion at 93% of transformer performance
- Question answering: 87% of transformer performance
- Multi-step reasoning: 74% of transformer performance
- Code generation: 68% of transformer performance
The gap narrows with scale—larger diffusion models perform better—but transformers still lead on tasks requiring multi-step logical reasoning.
Inference Efficiency Trade-offs
While diffusion enables parallel generation, the 50-100 denoising steps required for high quality eat into speed gains. Google’s analysis found:
- Low quality (10 denoising steps): 5x faster than transformers, but poor coherence
- Medium quality (50 steps): 2x faster, acceptable for simple tasks
- High quality (100+ steps): Only 1.2x faster, sometimes slower
Researchers are exploring faster samplers. Recent work from NVIDIA demonstrated techniques reducing required steps by 40% without quality loss, but this remains an active research area.
Industry Perspective and Timeline
Where the Big Labs Stand
No major AI company has bet entirely on diffusion for language yet, but interest is growing.
Google DeepMind leads in research output with 12+ diffusion language papers published since 2022. Their blog posts hint at future integration into Gemini models.
OpenAI hasn’t published much on diffusion language models, remaining focused on scaling transformers. Sam Altman’s statements suggest they view transformers as having “significant headroom” before needing architectural changes.
Anthropic (makers of Claude) has stayed quiet on diffusion research, though job postings mention “alternative architectures to transformers.”
Startup Activity
Several startups are betting on diffusion approaches:
- Together AI: Building infrastructure for training diffusion language models at scale
- Character.AI: Exploring diffusion for controllable character generation
- Various stealth startups in “alternative LLM architecture” space
Venture capital data from PitchBook shows $180 million invested in “next-gen language model architecture” startups in 2024—though not all focus on diffusion specifically.
Realistic Timeline
Experts predict 3-5 years before diffusion language models could challenge transformers in production systems.
Gartner’s assessment suggests:
- 2025-2026: First commercial diffusion language models for niche applications (text editing, controlled generation)
- 2027-2028: Diffusion models competitive with transformers on general tasks
- 2029+: Potential hybrid architectures combining transformer and diffusion strengths
Andrew Ng’s statements at AI conferences note that “architectural transitions in AI happen slowly”—even when new approaches show promise, the installed base of transformer-optimized infrastructure creates inertia.
The Comparison Matrix
| Aspect | Transformer LLMs | Diffusion LLMs | Advantage |
|---|---|---|---|
| Generation Speed | Sequential (slow) | Parallel (faster) | Diffusion (2-5x) |
| Text Quality | Excellent | Good (improving) | Transformer |
| Editing/Revision | Regenerate from point | Natural editing | Diffusion |
| Complex Reasoning | Strong | Moderate | Transformer |
| Training Maturity | Well-understood | Still developing | Transformer |
| Compute Efficiency | 1x baseline | 1.5-2x training cost | Transformer |
| Controllability | Prompt-based | Built-in | Diffusion |
| Deployment Ecosystem | Mature | Early | Transformer |
| Research Momentum | Plateauing | Accelerating | Diffusion |
Conclusion
Diffusion language models aren’t ready to replace transformers today, but they represent genuine architectural innovation worth watching. The fundamental advantages—parallel generation, natural editing, flexible control—address real limitations of autoregressive transformers.
Will they become “the next big trend”? Maybe. But more likely, we’ll see hybrid approaches combining transformer strengths (reasoning, quality) with diffusion advantages (speed, controllability).
The transformer revolution took 3-4 years from the 2017 paper to GPT-3 proving commercial viability. If diffusion language models follow a similar path from DiffusionLM’s 2022 introduction, we might see real commercial impact around 2025-2026.
For now, transformers reign supreme—but competition is emerging. And competition drives progress. Whether diffusion models take over or simply push transformers to evolve, the language AI field benefits from exploring alternative architectures.
The most exciting possibility? That five years from now, the best language models might use approaches we haven’t even invented yet.
Sources
- Attention Is All You Need - Original Transformer Paper - Google Research, 2017
- Papers With Code - Text Generation Benchmarks - 2024
- Google Research - Transformer Architecture Improvements - 2023
- Gartner - AI Predictions 2024 - 2024
- Princeton/Stanford - Autoregressive Generation Limits - 2023
- MIT Computational Linguistics - Text Editing Research - 2024
- OpenAI - AI and Compute Scaling - 2023
- DiffusionLM Paper - Stanford/Google - 2022
- Google Research - Diffusion Language Models Analysis - 2024
- Analog Bits - UC Berkeley - 2023
- NeurIPS 2024 - Diffusion Model Benchmarks - 2024
- Stanford NLP - Controllable Diffusion - 2024
- Google Plaid Paper - 2023
- Meta AI Research Publications - 2024
- SSD-LM - CMU - 2024
- HELM Language Model Evaluation - Stanford, 2024
Stay updated on AI architecture research.
Stay updated on AI architecture research.
Strategy needs execution. Cloud Geeks publishes practical cloud computing and cybersecurity guides for Australian businesses ready to act.
I lead Ganda Tech Services, where we turn digital strategy into results through specialist cloud, web design, and mobile app teams across Sydney.
About the Author
Ashish Ganda is the founder of Ganda Tech Services, a Sydney-based technology consultancy specialising in cloud infrastructure, web development, and mobile app solutions for Australian businesses.
AI Strategy Primer for Australian Business Leaders
A practical framework for AI adoption in 2026 — cut through the hype and start with what matters.