
Quality Gate Drift: The Post-Mortem on a Pipeline That Almost Shipped Broken Content
Quality Gate Drift: The Post-Mortem on a Pipeline That Almost Shipped Broken Content
In software engineering, there is a class of failure that is not dramatic. No servers go down. No alerts fire. No one is paged at 2:00 AM. The system runs exactly as configured. The problem is that the configuration is wrong — and has been slowly drifting from what it should be for weeks.
This is a post-mortem on that kind of failure.
Background: The Automated Publishing Pipeline
We run a content automation system that publishes approximately 22 blog posts per month across seven branded websites. The system generates content using AI, passes it through SEO and quality checks, injects cross-links, generates images, and pushes finished posts to Git repositories for automatic deployment.
For the full architecture, see: How We Built an AI Blog Factory: 22 Posts Per Month Across 7 Sites.
The pipeline had been running smoothly for about three months. We had good tooling, a working scheduler, and a dashboard where we could monitor jobs. Then two posts published at 300 words each.
The Incident
Date discovered: 2026-03-09 Duration of exposure: 4 days Posts affected: 2 Sites affected: cosmos, contentsage User impact: None directly, but two posts were live and indexable at 1/4 the minimum quality standard
What We Found
Two posts were live with approximately 300 words each. Both had valid frontmatter, valid images, correct cross-links. The pipeline had reported them as completed successfully.
Neither was close to the minimum quality threshold.
Our minimum word count for cosmos is 1,200 words. Our minimum for contentsage is 1,200 words. The published posts were 300 and 340 words respectively — roughly 25% of the minimum.
Why the Pipeline Didn’t Catch It
This is where the post-mortem gets interesting.
The pipeline did have a word count check. It was documented in the README. It was mentioned in a code comment. It was specified in a planning document written when the system was designed.
But when we traced the actual execution path, the check was:
Pseudocode of what the word count check actually did:
function validateContent(post):
wordCount = countWords(post.body)
if wordCount < 800:
// This threshold was hardcoded here in January
// The README says 1,200 but nobody updated this
log.warning("Post is short but proceeding")
return true // ← Logged warning, but didn't fail
return trueThree problems in one function:
-
The threshold was wrong. The code had
800words as the minimum, but the README said1,200. Somewhere between the planning document and the code, the number had been lowered — likely during a period when AI generation quality was inconsistent and we wanted to avoid too many failures. -
The check was a warning, not a gate. Even at 800 words, the check logged a warning and returned
true. It never actually failed the job. -
There was no single source of truth. The threshold existed in at least four places: the README, the planning document, a comment in the code, and the hardcoded value in the function. They had four different numbers.
The Root Cause: Quality Gate Drift
This is the pattern we named “quality gate drift.”
It happens in phases:
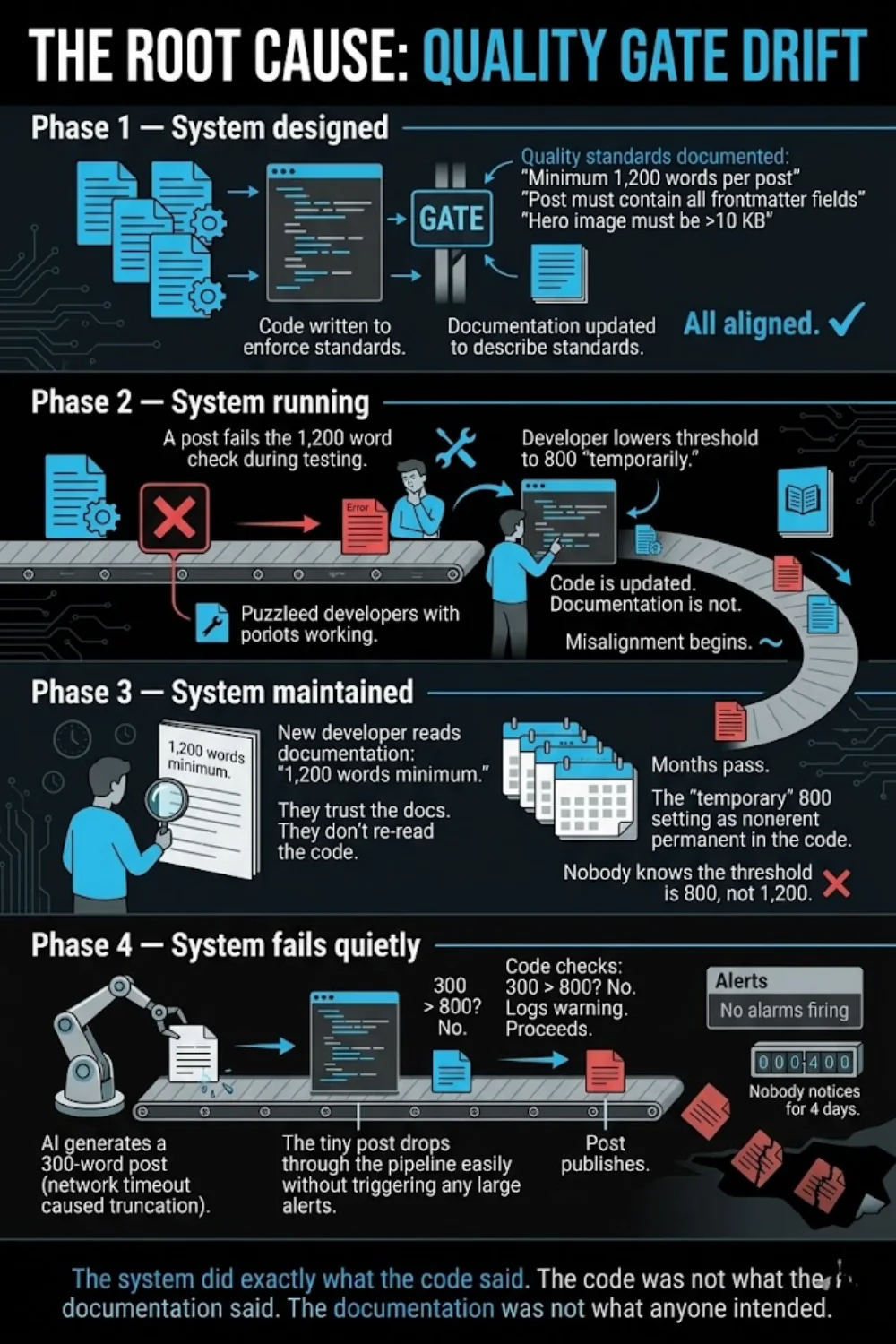
The system did exactly what the code said. The code was not what the documentation said. The documentation was not what anyone intended.
The Cross-Skill Code Review That Caught Everything
The 300-word posts were just the visible symptom. When we ran a thorough cross-skill code review of the entire pipeline in late March 2026, we found nine more latent issues:

Issue #10 was the root cause of most of the others. Because quality constants were scattered across the codebase, each was independently maintained — or not maintained — and they drifted apart.
The Fix: Single Source of Truth for Quality Constants
The architectural fix was simple but required discipline to implement consistently.
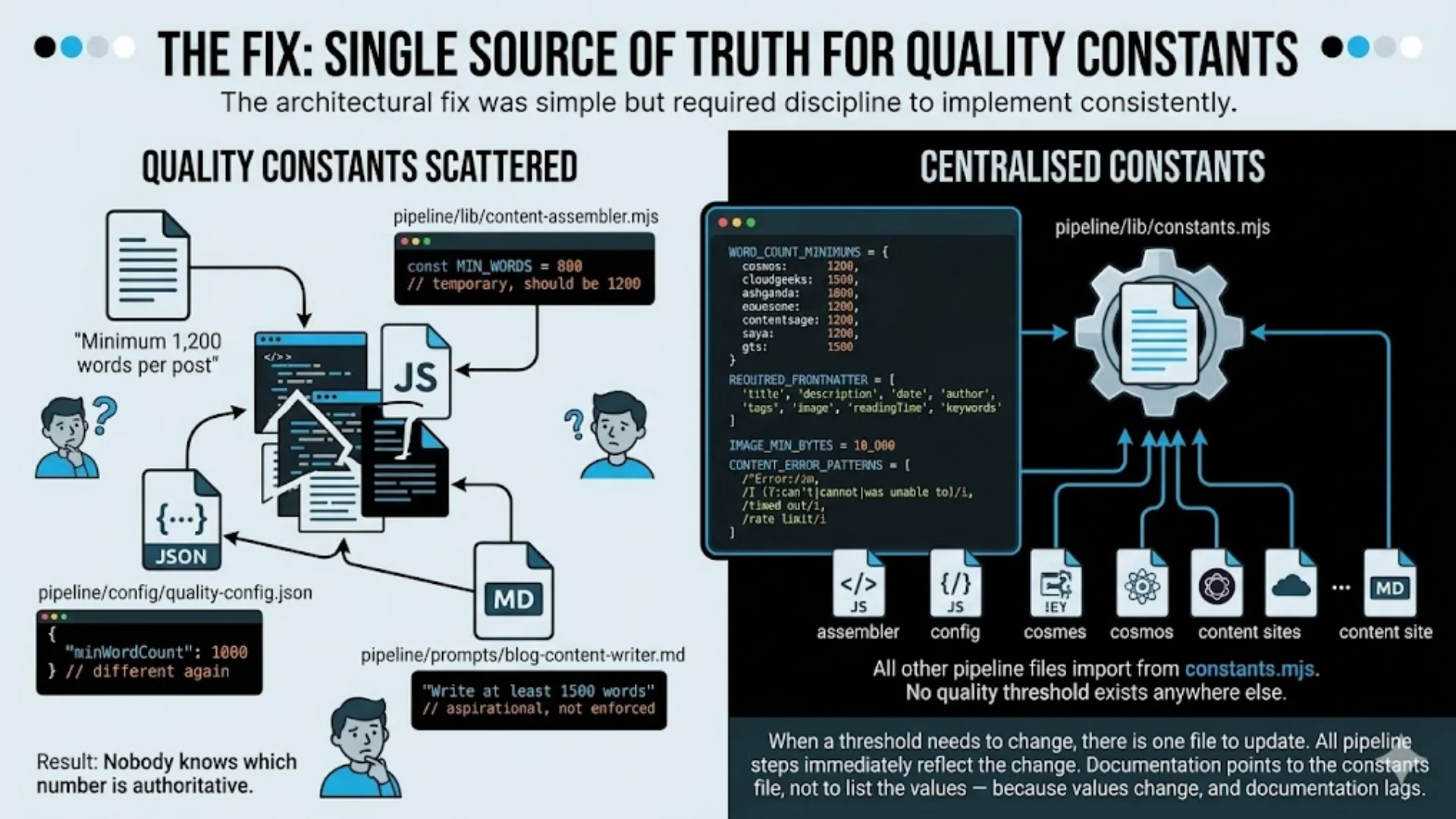
When a threshold needs to change, there is one file to update. All pipeline steps immediately reflect the change. Documentation is updated to point to the constants file, not to list the values — because values change, and documentation lags.
Quality Gates That Actually Fail
The second fix: every quality check must fail the job, not log a warning.
The pattern “log a warning and proceed” is almost always wrong for a gate. A gate that does not stop traffic is not a gate. It is a speed bump with a logging sidebar.
The right pattern:

A job that fails at validation is marked failed in the calendar. It does not publish. It does not mark as completed. It alerts us for review. That is the correct behaviour.
The Cross-Skill Code Review as a Practice
This incident led us to establish a regular cross-skill code review as a formal practice.
The idea is simple: have someone who did not write the pipeline review it against the documented intent, not the code intent. The reviewer asks:

Our March 2026 code review found 10 issues. None were caught by our automated tests (which tested happy paths) or our linter (which checks syntax, not semantics). They were found by a human reading the code against the system’s intended behaviour.
We now do this review every quarter, or after any significant pipeline change.
What Quality Gate Drift Looks Like in Other Systems
This pattern is not unique to content pipelines. It appears wherever:
- Standards are documented but not enforced in code — the documentation becomes aspirational rather than authoritative
- Teams grow or change — new members read the docs and trust them; they don’t know the code diverged
- “Temporary” changes become permanent — every production system has at least one setting that was “temporary” six months ago
- Multiple systems share a value — each maintains its own copy; they drift
Common examples:
Where quality gate drift typically hides:
──────────────────────────────────────────
CI/CD pipelines:
"Minimum 80% test coverage" in the README
Actual coverage gate set to 60% in the config
API rate limiting:
"100 requests per minute per user" in the spec
Actual limiter set to 1000 "while we tune it"
Tuning never happened
Data validation:
"Fields X and Y are required" in the data model
Actual validator checks X but not Y
Y has been optional in practice for months
Financial systems:
"Transactions above $10,000 require approval" in policy
Actual approval trigger set to $50,000 after an incident
Policy document never updatedThe mitigation in every case is the same: make the authoritative value live in the code, and have the documentation point to the code. Not the other way around.
Lessons for Technology Leaders
If you are running automated systems at any scale — content pipelines, data pipelines, deployment pipelines, financial systems — here are the takeaways from this incident:
1. Documentation describes intent. Code describes reality. When they diverge, reality wins. Resolve the divergence toward code or toward documentation — but resolve it, don’t leave it.
2. Quality gates that don’t fail are not quality gates.
Audit your pipeline for log.warning("short but proceeding") patterns. Every one of them is a gate that has been opened permanently.
3. Cross-skill code reviews catch what tests don’t. Tests verify happy paths and known edge cases. A code review against documented intent catches drift, semantic errors, and “temporary” changes that became permanent.
4. Single source of truth scales; scattered constants don’t. If a threshold value appears in more than one place in your system, one of them is wrong. You just don’t know which one yet.
Previous post in this series: How We Built an AI Blog Factory: 22 Posts Per Month Across 7 Sites
Related: Why Code Reviews Across Skills Catch What Tests and Linting Miss — 10 Issues Found
The strategic frameworks I discuss here come to life through execution. Cloud Geeks covers the practical side of cloud infrastructure and IT management.
As founder of Ganda Tech Services, I work with Australian businesses to align technology investments with business growth — across cloud, web, and mobile.
Digital Transformation Roadmap 2026
A 12-month framework for Australian SMBs ready to modernise — phases, tools, and milestones.